

Legal professionals read, write and reason about the law using language. While that language is relatively straightforward to us, no computer can process and communicate it in the same way.
To a limited extent, computers can use information extraction to identify, process and transmit relevant portions of legal text to us. Another way for computers to process language in a meaningful way is to enrich it with additional, implicit information — turn strings of text characters that are meaningless to the machine into information that is meaningful to legal professionals. For this, we use Semantic Web technology.
The Semantic Web extends the current World Wide Web by making Web-based documents meaningful to both people and computers. To realize the Semantic Web, several tools are used. In Legal Ontologies Spin a Semantic Web, we discussed one tool, ontologies, which represent structured, semantic domain knowledge. In this article, we outline another tool, extensible markup languages (XML), which can be viewed as a syntactic expression of knowledge. We introduce the problem which XML addresses, some of the broad concepts of XML, a short example, comment on the relationship between XML and ontologies, and provide some tools and sources of further information and tools.
WHAT’S IN A WEB PAGE?
By way of introducing what XML addresses, suppose a legal professional wants to review a legislative bill on the Web. The U.S. House of Representatives has sample legislation available such as in Figure 1.

Figure 1. U.S. House of Representative Bill No. 3701
With a little instruction and common sense, we can read the bill and answer questions:
• What is the number of the legislation?
• What is the official title of the Bill?
• Who sponsored and co-sponsored the Bill?
• What is in section 1?
Given a corpus of bills, we could manually gather together all bills of a certain sort, say those introduced by a particular legislator and referred to the Committee on the Judiciary. There might be additional information which is not explicit in the document such as whether the bill has been passed or not.
Given our linguistic capacities, we understand what we read, but a computer cannot because to a computer the text is just a sequence of character strings which lack syntax and semantics. Using linguistic information extraction technology, one can train a computer to automatically identify the parts of the text or sort the documents, then answer a query. For example, strings at the top of the page such as “H.R.” followed by a number in bold and after the string “CONGRESS” provide the bill number. Other tasks are more difficult, such as identifying a sponsor. However, current extraction technology is not yet reliable and thorough enough to be useful.
Rather than extracting information from raw text, we can explicitly indicate in the document what certain strings signify. An alternative view of Bill 3701 is in Figure 2, which is a partial XML version of the same document that the computer “sees”; what we see is generated from the XML version of the document.
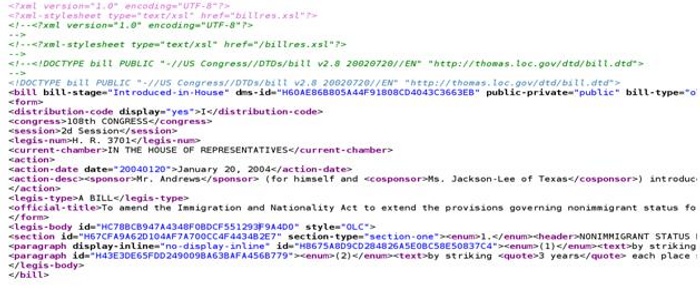
Figure 2. XML Version of Bill No. 3701
In this view, we find the same text as in Figure 1, but there is additional material to help computers locate specific pieces of information. For example, there are pairs of tags (a beginning and ending tag) such as those used in H.R. 3701; such tags tell computers that the string between the tags should be taken to have a particular meaning, namely, the number of the legislation. Thus, rather than using information extraction techniques, we request the computer to search through a corpus of legislation for just that information between specified tags. A computer is especially good at such a task.
WHAT IS XML?
XML stands for Extensible Markup Language. As we have seen, it is used to mark up information in a Web document, indicating the meaning or use of the data between the markups. Plain ASCII text is used to present the markup, allowing the markup to be processed by humans and machines alike. Some of the advantages of an XML markup are:
• The data is separated from the visual presentation. In Figure 2, the XML version does not indicate what data is centered, indented or in bold. The same data can be presented in different ways. A separate process provides the visual layout.
• The data can be easily shared, transmitted and processed since it is in a public, standardized, machine-readable format.
• XML provides a standard for markup languages. Following the standard, one can create a markup language (extensibility) for almost any purpose; for instance, there is a Chemical Markup Language and a Mathematics Markup Language.
To create XML, one must adhere to some specification rules. We must have pairs of tags such as … , where Z is some meaningful information like “official-title,” and the tags indicate the beginning and ending of a specific portion of data. An element is a pair of tags along with the data contained between them. Furthermore, the structure of the tags must be tree-like in the sense of being properly nested (i.e., no overlapping tags), having a root with children, and children with subchildren portions. If a document adheres to the specification of a given XML, then it is a well-formed XML document and can be processed further.
A LEGAL XML
To see how XML is realized in the legal domain, we take apart our example in Figure 2. The structure of the tags reflects the structure of the document. For simplicity, we remove some elements. At the highest level, we have tags for the structure of the legislation, where the root is “bill” and the children are “form” and “legis-body,” which are the main parts of a bill in its XML format.
This content has been archived. It is available through our partners, LexisNexis® and Bloomberg Law.
To view this content, please continue to their sites.
Not a Lexis Subscriber?
Subscribe Now
Not a Bloomberg Law Subscriber?
Subscribe Now
LexisNexis® and Bloomberg Law are third party online distributors of the broad collection of current and archived versions of ALM's legal news publications. LexisNexis® and Bloomberg Law customers are able to access and use ALM's content, including content from the National Law Journal, The American Lawyer, Legaltech News, The New York Law Journal, and Corporate Counsel, as well as other sources of legal information.
For questions call 1-877-256-2472 or contact us at [email protected]



